Hello,
I present a use case of a beam modeled in Ansys where the goal is to reduce the variability of an output. The model here is a simple beam subjected to a central force and with limited displacements at the extremity as boundary conditions.


The coupling with Ansys is described in detail in this Persalys news. I will focus the analysis only on the deviation output coming from the 1st block and I changed the parameter names in Persalys for the sake of an easier understanding. The parameters inputs and outputs are shown in the figure below.
In Ansys:

In Persalys:

All inputs are defined as Normal random variable with a coefficient of variation of 10%.
Analysis
First I create of design of experiment LHS of size 100 and I evaluate the points with the coupling model. And then I obtain the table of the inputs and outputs as shown below:

If if look at the summary, I can see that the computing time was more than 9000 s being about 2h30 and also that my deviation has a great coefficient of variation, around 45%. I would like to reduce this variability by reducing the variability of some influential inputs.

In order to find on which inputs I must focus on, let’s have a look on the plot matrix in the rank space (with the relevant variables selected). It shows that the variability of the computed deviation (disp\_P5) seems to mainly come from the height h\_P11 and the length L\_P9 which is confirmed by the Spearman correlation values in the dependence tab.

So now it seems that if I reduce the variability of these 2 inputs, I will reduce the variability of my deviation but I want to estimate what will be this new variability. To do that, I will first create a metamodel using the computed design of experiments. Here I build a sparse polynomial chaos model of degree 3 and I obtain a nice curve fitting graph and a R2 > 0.999 and a Q2 > 0.98, so I am confident to use it as a surrogate model for other analyses.

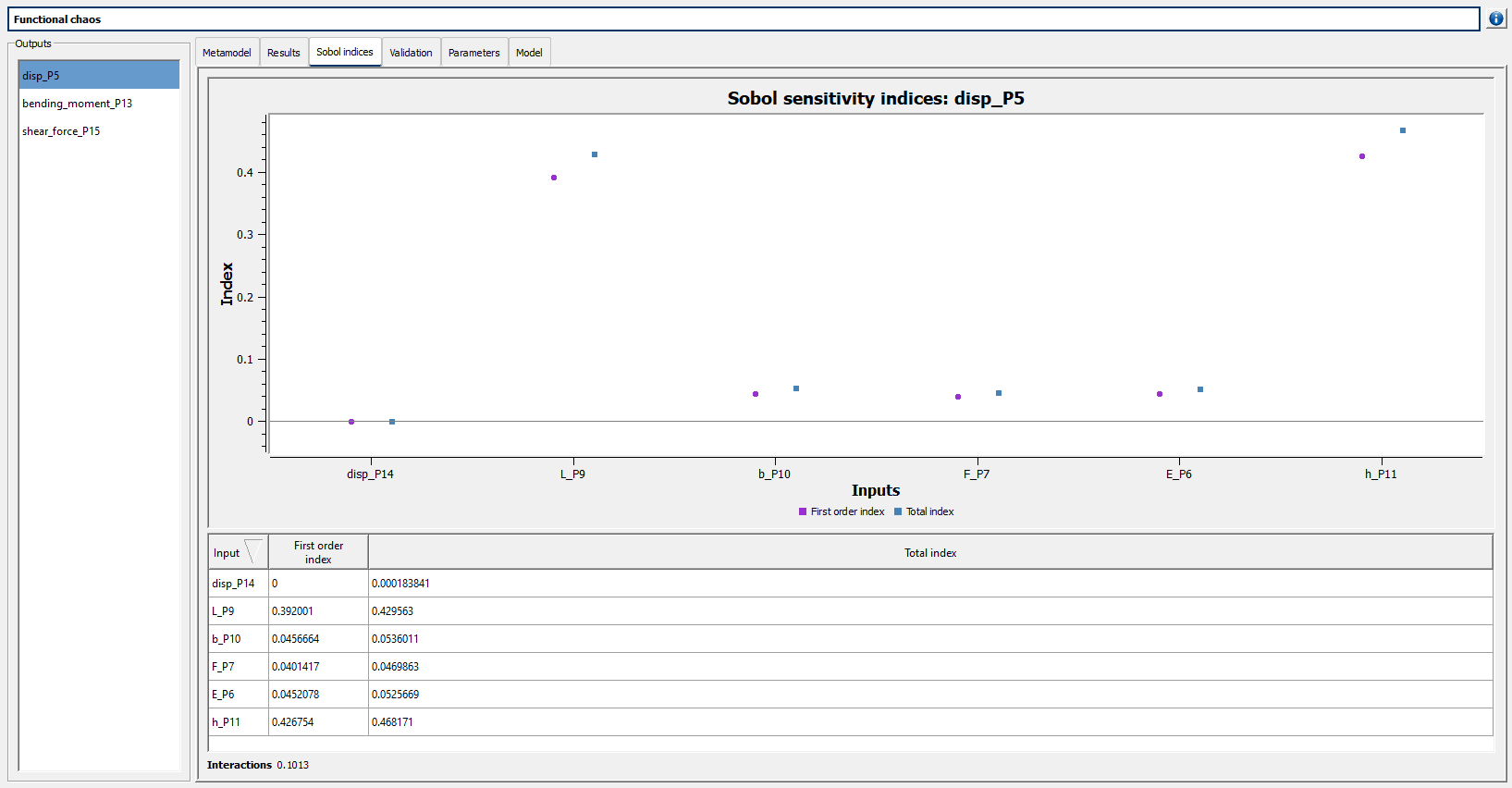
As I chose the polynomial chaos, I automatically get the Sobol Indices (global sensitivity indices) which confirms that the variability of h\_P11 and L\_P9 are responsible of more than 80% of the deviation variability.
I can now export this metamodel as a real model.

Now I will change the variability of these to inputs in the probabilistic model of the metamodel, dividing by 2 their standard deviation: \sigma_{L\_P9} = 0.6 / 2 and \sigma_{h\_P11} = 0.04 / 2.
I can then run a central tendency analysis with Monte Carlo really quickly because I use the metamodel. I did more than 900 calls in less than 1s and now I see that the coefficient of variation of the deviation is reduced to 30%, hence reducing also the risk of failure of the beam when exceeding an ultimate tensile strength.

